
过去几年,本地部署大模型始终面临一个核心矛盾:想要高性能,就必须用百亿甚至千亿参数的大模型,算力成本高到普通用户和中小团队难以承受;想要低成本,就只能用小参数模型,推理能力和智能体表现又跟不上需求。Gemma 4 的出现哪个证券公司可以加杠杆,直接改写了这一格局。

谷歌 DeepMind 正式发布 Gemma 4 开源模型系列,给整个 AI 行业投下了一颗重磅炸弹。这款专为高级推理和智能体工作流设计的模型,以 Apache 2.0 许可开源,支持用户在自有硬件上本地运行,彻底打破了本地部署大模型的算力壁垒。
一、小参数,大能量
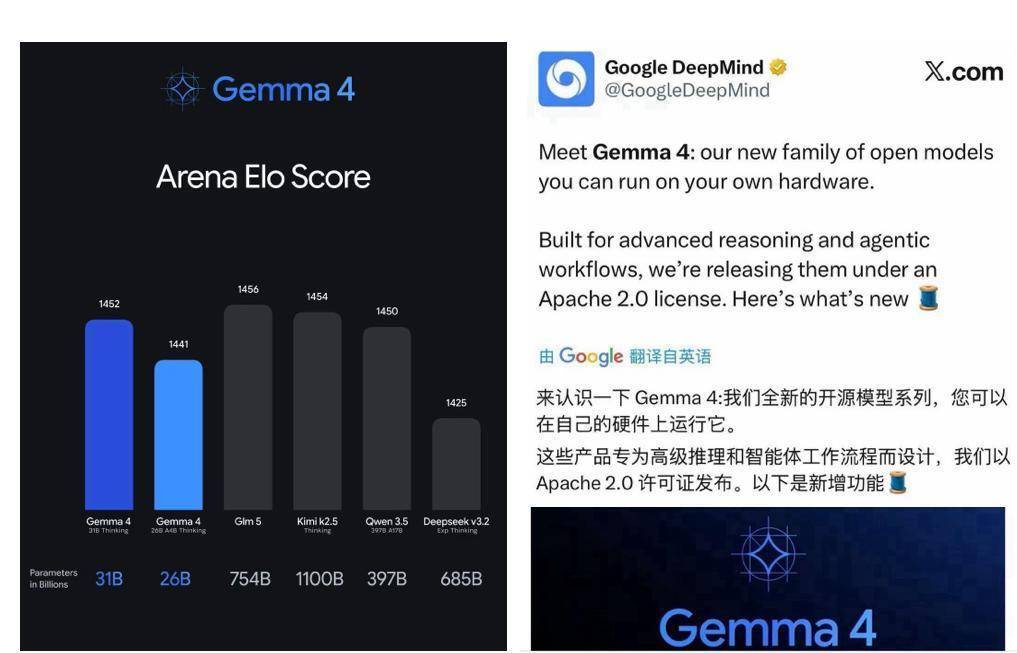
从谷歌公开的 Arena Elo 评分数据来看,Gemma 4 的表现完全超出了市场预期。31B 参数的 Gemma 4 Thinking 版本,Elo 评分达到 1452 分,26B 参数的 Gemma 4 A4B Thinking 版本,评分也达到 1441 分。
这一成绩,直接追平甚至超越了多款千亿级参数的国产大模型。GLM 5 以 754B 参数拿到 1456 分,Kimi k2.5 以 1100B 参数拿到 1454 分,Qwen 3.5 以 397B 参数拿到 1450 分,Deepseek v3.2 以 685B 参数拿到 1425 分。Gemma 4 用仅 31B 的参数规模,实现了和千亿级模型几乎持平的推理能力,参数效率提升了数十倍。
这种参数效率的飞跃,是 Gemma 4 最核心的价值。它意味着,用户不再需要为了高性能,投入几十万的算力成本,也不再需要依赖云端 API,就能在本地硬件上,运行具备高级推理能力的大模型。对于很多开发者和团队来说,这已经不是「能聊天」的级别,而是能进工作流的级别。
二、本地部署算力成本历史性下降
本地部署大模型的核心门槛,从来都是算力成本。过去,想要部署一款具备实用推理能力的大模型,至少需要 A100、H100 这类高端 GPU,单卡成本就超过 10 万元,中小团队和个人用户根本无法承担。
Gemma 4 的出现,彻底拉低了本地部署的算力门槛。31B 参数的模型,在量化优化后,仅需单张消费级 GPU 就能流畅运行。比如 RTX 4090、RTX 4080 这类主流游戏显卡,就能轻松承载 31B 模型的本地推理,单卡成本仅 1-2 万元,甚至部分优化版本,能在 RTX 3090 上稳定运行。和过去的本地部署方案相比,算力成本下降了一个数量级。以往部署千亿级模型,需要多卡集群,算力成本动辄几十万;现在,单张消费级显卡,就能跑通具备高级推理能力的大模型,个人用户、2-3 人的小团队,都能轻松承担。
更关键的是,Gemma 4 支持本地优先部署,所有数据都存储在用户自有硬件中,无需上传云端,彻底解决了数据隐私和合规问题。对于企业用户而言,本地部署能避免核心数据泄露,符合国内数据安全法规要求;对于个人用户而言,本地部署能摆脱 API 调用的限制,实现 7×24 小时离线使用,不受平台规则约束。
三、对本地部署生态的深远影响
Gemma 4 的发布,不仅是一款模型的迭代,更是本地部署大模型生态的一次全面升级。
首先,它彻底激活了个人和中小团队的 AI 创业空间。以往,本地部署大模型是大厂和专业团队的专属,个人用户只能使用云端 API,受限于平台规则和调用成本。现在,个人用户可以用消费级硬件,本地部署高性能大模型,搭建专属 AI 助手、智能体工作流,甚至开发垂直行业解决方案,实现 AI 变现。
其次,它推动了本地智能体的规模化落地。Gemma 4 专为智能体工作流设计,具备强大的高级推理能力,能完美适配本地智能体的全链路需求。用户可以在本地搭建 7×24 小时在线的 AI 智能体,对接各类办公、社交平台,实现流程自动化、客户服务、内容生成等多元场景的落地,无需依赖云端服务。
再次,它加速了开源大模型的技术迭代。Gemma 4 以 Apache 2.0 许可开源,允许用户自由修改、二次开发、商用,彻底放开了技术壁垒。开发者可以基于 Gemma 4,优化模型结构、适配垂直行业、开发配套工具,进一步推动本地部署大模型的技术进步,形成良性的生态循环。
主流科技媒体对 Gemma 4 的发布,普遍给出了高度评价。海外科技媒体认为,Gemma 4 的参数效率突破,是开源大模型领域的里程碑事件,将彻底改变本地部署大模型的市场格局,让 AI 真正走向普惠。国内行业媒体则指出,Gemma 4 的发布,将倒逼国产开源大模型加速技术迭代,推动国内本地部署生态的完善。
四、普通人如何抓住这波新机会?
Gemma 4 的发布,给普通用户和中小团队,带来了前所未有的机会。不用巨额的算力投入,不用深厚的技术背景,就能抓住本地部署大模型的红利。
对于个人用户而言,可以用 Gemma 4 搭建专属 AI 助手,提升日常工作效率。比如搭建个人办公助手,自动完成文档撰写、邮件回复、日程管理;搭建学习助手,实现知识点梳理、习题解答、学习计划制定;搭建创作助手,批量生成内容、优化文案、设计脚本,用 AI 放大个人产能。
对于中小团队而言,可以基于 Gemma 4,开发垂直行业的 AI 解决方案,实现商业变现。比如给中小企业搭建本地智能客服,自动完成客户咨询、订单处理、售后跟进;给传统行业搭建行业专属 AI 助手,优化业务流程、提升运营效率;开发本地部署的 AI 工具包,卖给有需求的企业用户,实现稳定的订阅收入。
对于开发者而言,可以基于 Gemma 4 的开源框架,开发配套工具、优化模型性能、搭建技能市场,服务本地部署生态。比如开发一键部署工具,帮用户快速完成 Gemma 4 的本地安装;开发垂直行业技能包,卖给行业内的用户;搭建本地智能体交易市场,实现生态内的商业变现。
五、本地部署大模型的未来趋势
Gemma 4 的发布,标志着本地部署大模型的春天,正式到来。未来,本地部署大模型将呈现三大发展趋势。
第一,参数效率持续提升,算力门槛持续下降。随着模型架构的优化、量化技术的进步,未来会有更多小参数、高性能的开源大模型出现,本地部署的算力门槛会进一步降低,甚至能在手机、平板等移动设备上,运行具备实用能力的大模型。
第二,本地智能体成为主流应用场景。本地部署大模型的核心优势,是数据可控、隐私安全,这与智能体的工作流需求高度契合。未来,本地智能体将成为 AI 应用的主流形态,用户可以在本地搭建专属 AI 员工,完成全链路的工作自动化,无需依赖云端服务。
第三,开源生态持续繁荣,普惠 AI 加速落地。Apache 2.0 的开源许可,将吸引全球开发者参与到 Gemma 4 的生态建设中,推动模型优化、工具开发、场景落地的全面发展。本地部署大模型将不再是大厂的专属,而是成为普通用户、中小团队都能使用的普惠工具。
结尾
Gemma 4 的发布,是 AI 行业的一个重要转折点。它用小参数、高性能的开源模型,彻底打破了本地部署大模型的算力壁垒,让 AI 真正走向普惠。
对于每一个关注 AI 发展的人而言,Gemma 4 的发布,都是一个值得抓住的机会。从本地部署第一个 Gemma 4 模型开始,搭建属于自己的 AI 助手,探索属于自己的 AI 变现路径,每个人都能在本地部署大模型的春天里,拿到属于自己的结果。
作者:实战产品说 公众号:实战产品说
本文由 @实战产品说 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议
该文观点仅代表作者本人哪个证券公司可以加杠杆,人人都是产品经理平台仅提供信息存储空间服务。
长富资本提示:文章来自网络,不代表本站观点。




